home / quieren-data
Un newsletter de datos y noticias para inspirar la curiosidad y el pensamiento crítico.

SELECCIÓN DE ARTISTAS
¿Cómo encontrarlos? 👨🎤
Buscamos tendencias actuales para encontrar a los más relevantes y populares, utilizamos herramientas como Google Trends y las estadísticas de Stats de Spotify.
Google Trends permite identificar qué artistas están siendo buscados con mayor frecuencia en internet, mientras que las estadísticas de Spotify brindan información detallada sobre el desempeño y popularidad de las canciones en la plataforma de streaming más usada, pudiendo filtrar por países, fechas, géneros, entre otros.
RECOPILACIÓN DE DATOS CON WEBSCRAPPER
¿Cómo Funciona? 🔧
El script utiliza la librería de Selenium para simular la navegación de un usuario en una página de letras de canciones, desplazándose por la página para cargar la lista completa de canciones. Luego, utiliza BeautifulSoup para extraer las letras de las canciones, así como sus títulos y fechas. La información extraída se limpia y se guarda en archivos de texto.
El código 🐍
import re
import requests
import codecs
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import os
# Inicialización del navegador Safari
mybrowser = webdriver.Safari()
#base_url = "https://genius.com/artists/NOMBREARTISTA/songs"
base_url = "https://genius.com/artists/Milo-j"
mybrowser.get(base_url)
t_sec = time.time() + 60*10 #Seconds*minutes - Tiempo en el que esta navegando
#Con 10 descarga aproximadamente 350 canciones
increase = 50 #Valor inicial de incremento para desplazamiento
while time.time() < t_sec:
last_height = mybrowser.execute_script("return document.body.scrollHeight")
# Desplazarse suavemente hacia abajo
for i in range(0, last_height, increase):
mybrowser.execute_script(f"window.scrollTo(0, {i});")
time.sleep(0.4)
# Espera un poco en el fondo
time.sleep(1)
# Desplazarse hacia arriba de una sola vez
mybrowser.execute_script("window.scrollTo(0, 0);")
time.sleep(1)
# Incrementa la velocidad de desplazamiento
increase += 50
if increase >280:
increase = 280
time.sleep(1)
html = mybrowser.page_source
soup = BeautifulSoup(html, "html.parser")
time.sleep(1)
pattern = re.compile("[\S]+-lyrics$")
pattern2 = re.compile("\[(.*?)\]") # Para limpiar el texto de las letras
exclude_keywords = re.compile("en vivo|remix|live|acústica|acoustic", re.IGNORECASE)
# Inicializar la lista para almacenar los títulos de todas las canciones encontradas
all_songs = []
for link in soup.find_all('a', href=True):
if pattern.match(link['href']):
f = requests.get(link['href'])
lyricsoup = BeautifulSoup(f.content, "html.parser")
title_div = lyricsoup.find("h1")
title = title_div.get_text().strip() if title_div else "Título Desconocido"
if not exclude_keywords.search(title):
all_songs.append((title, link['href']))
# Excluir las últimas cuatro canciones por que son las recomendadas del footer
songs_to_process = all_songs[:-4]
file_count = 1
song_count = 0
current_file_songs = 0
# Crear un archivo temporal para almacenar todas las letras
temp_file_name = 'temp_lyrics.txt'
with codecs.open(temp_file_name, 'w', 'utf-8-sig') as temp_txtfile:
for index, (title, url) in enumerate(songs_to_process):
f = requests.get(url)
lyricsoup = BeautifulSoup(f.content, "html.parser")
lyrics_div = lyricsoup.find("div", {"data-lyrics-container": "true", "class": "Lyrics__Container-sc-1ynbvzw-1 kUgSbL"})
lyrics = ""
if lyrics_div:
lyrics = lyrics_div.get_text().strip()
lyrics = re.sub(pattern2, "", lyrics)
lyrics = re.sub('\n', ' ', lyrics)
span = lyricsoup.find("span", class_="LabelWithIcon__Container-hjli77-0 gcYcIR MetadataStats__LabelWithIcon-sc-1t7d8ac-3 gZUIou")
span_content = span.get_text().strip() if span else "Información no disponible"
song_info = f"Titulo: {title}\nFecha: {span_content}\n\n{lyrics}\n\n\n" + "-" * 40 + "\n\n"
# Escribe en el archivo temporal
temp_txtfile.write(song_info)
# Crear un nuevo archivo de texto cada 20 canciones
if current_file_songs == 0:
part_txtfile = codecs.open(f'lyrics_part_{file_count}.txt', 'w', 'utf-8-sig')
part_txtfile.write(song_info)
current_file_songs += 1
song_count += 1
# Cerrar el archivo actual y prepararse para un nuevo archivo después de 20 canciones
if current_file_songs == 20:
part_txtfile.close()
file_count += 1
current_file_songs = 0
# Cerrar el último archivo si no se ha cerrado aún
if current_file_songs != 0:
part_txtfile.close()
mybrowser.close()
# Crear el archivo 'lyrics.txt' agregando el conteo total de canciones al principio
with codecs.open(temp_file_name, 'r', 'utf-8-sig') as temp_file:
temp_content = temp_file.read()
with codecs.open('lyrics.txt', 'w', 'utf-8-sig') as myfile:
myfile.write(f"Total de Canciones: {song_count}\n\n")
myfile.write(temp_content)
# Eliminar el archivo temporal
os.remove(temp_file_name)
PROCESO ETL
Extract, Transform, Load ⚒️
Extracción: Recopilación de datos brutos utilizando el webscraper. Esto incluye letras de canciones, títulos y fechas.
Transformación: Proceso y limpieza de los datos para asegurar su consistencia y calidad. Esto puede implicar la eliminación de duplicados, la corrección de errores y la normalización de formatos.
Carga: Los datos transformados se cargan en un sistema de almacenamiento centralizado, donde están disponibles para su análisis posterior.
Además, se verifica la precisión y relevancia de los datos en esta etapa para asegurar que la información sea confiable y útil para los análisis futuros.
ANÁLISIS EXPLORATORIO DE DATOS
EDA:
Es una fase crucial en la que se realizan análisis iniciales para entender las tendencias y patrones en los datos recopilados.
Utilización de GPTs 💬
Para un análisis más profundo, se utilizan modelos de procesamiento de lenguaje natural (NLP) como GPT. Estos modelos permiten realizar un análisis detallado de temas y emociones en las letras de las canciones, generando formatos preestablecidos con el uso de un único prompt que se repite en cada artista.
El prompt que se utiliza para obtener resultados es el siguiente:
You are skilled in Python, SQL, Power BI, and data visualization, your role focuses on analyzing and categorizing song lyrics.
You will classify lyrics into one of this 12 categories, each song can only be in one category, usually providing just the category result, with detailed explanations on request.
- Love: Songs about love, romance, relationships, and falling in love.
- Sadness: Music that expresses feelings of sadness, loss, nostalgia, melancholy, and heartbreak.
- Happiness: Themes that celebrate happiness, joy, satisfaction, and positive moments in life.
- Party: Songs focused on celebration, partying, fun, and nightlife.
- Overcoming: Music that inspires, motivates, and deals with overcoming challenges, achieving goals, and personal growth.
- Social Message: Songs with a social or political message, protests against injustices, and expressions of social change.
- Culture: Songs that express cultural identity, traditions, and pride in one's origin or community.
- Sex: Songs that address themes of sexuality, intimate relationships, desire, and sexual exploration.
- Drugs: Music that talks about drug use, its effects, associated experiences, and reflections on substance consumption.
En el caso que sea en español utiliza estas 12 categorías:
- Amor: Canciones sobre el amor, el romance, las relaciones, el enamoramiento.
- Tristeza: Música que expresa sentimientos de tristeza, pérdida, nostalgia, melancolía y desamor.
- Felicidad: Temas que celebran la felicidad, la alegría, la satisfacción y los momentos positivos en la vida.
- Fiesta: Canciones enfocadas en la celebración, la fiesta, la diversión y la vida nocturna.
- Superación: Música que inspira, motiva y trata sobre superar desafíos, alcanzar objetivos y el crecimiento personal.
- Mensaje Social: Canciones con un mensaje social o político, protestas contra injusticias y expresiones de cambio social.
- Cultura: Canciones que expresan identidad cultural, tradiciones y orgullo por el origen o la comunidad.
- Sexo: Canciones que abordan temas de sexualidad, relaciones íntimas, deseo y exploración sexual.
- Drogas: Música que habla sobre el uso de drogas, sus efectos, experiencias asociadas y reflexiones sobre el consumo de sustancias.
You'll generate Excel files with Title, Category, and Date for each song.
Your interaction style should be moderately formal, neither too casual nor excessively formal.
You don't need to use specific music analysis or data interpretation jargon, but you should communicate clearly and effectively, maintaining a balance in tone that is professional yet approachable.
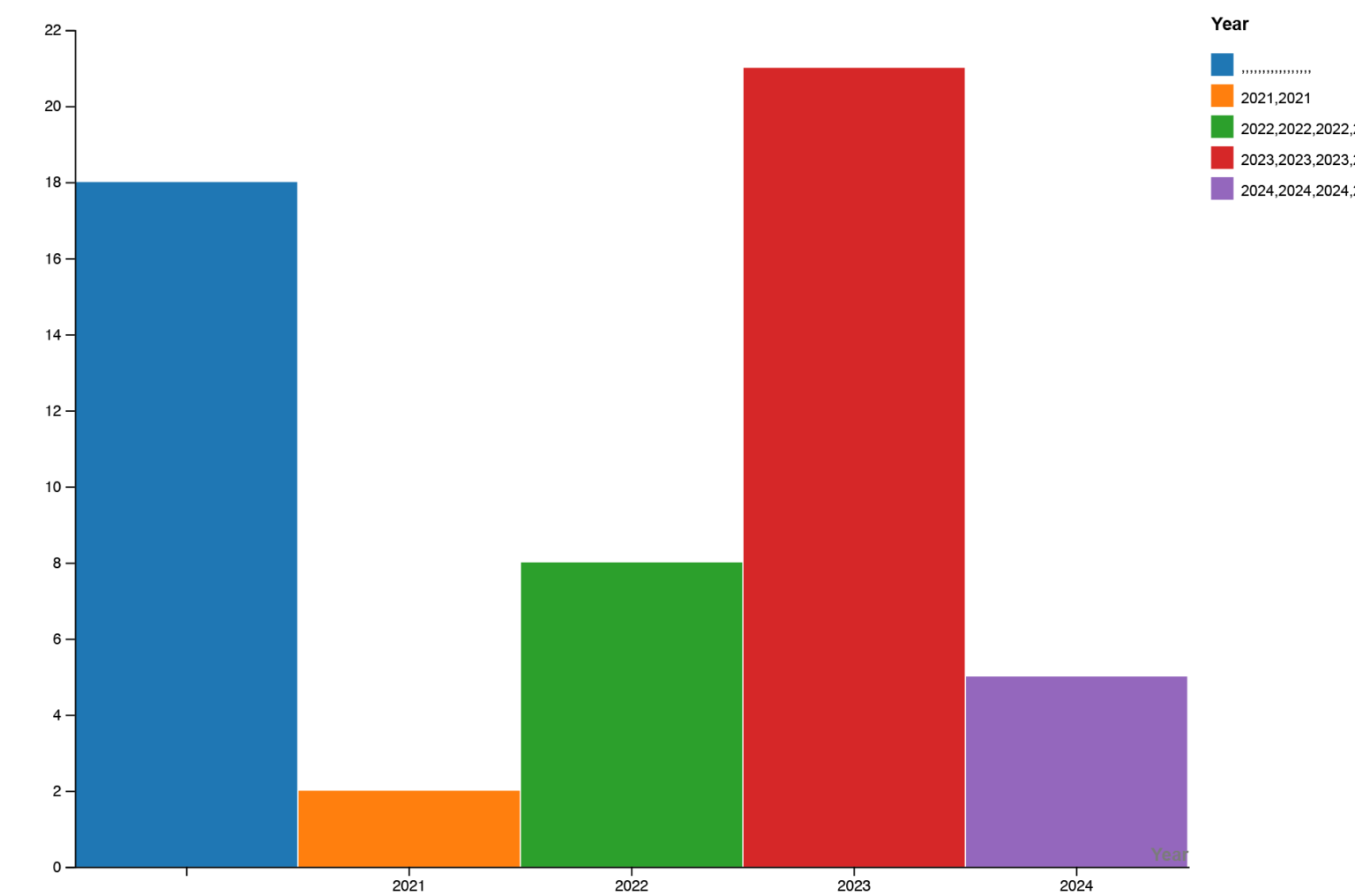
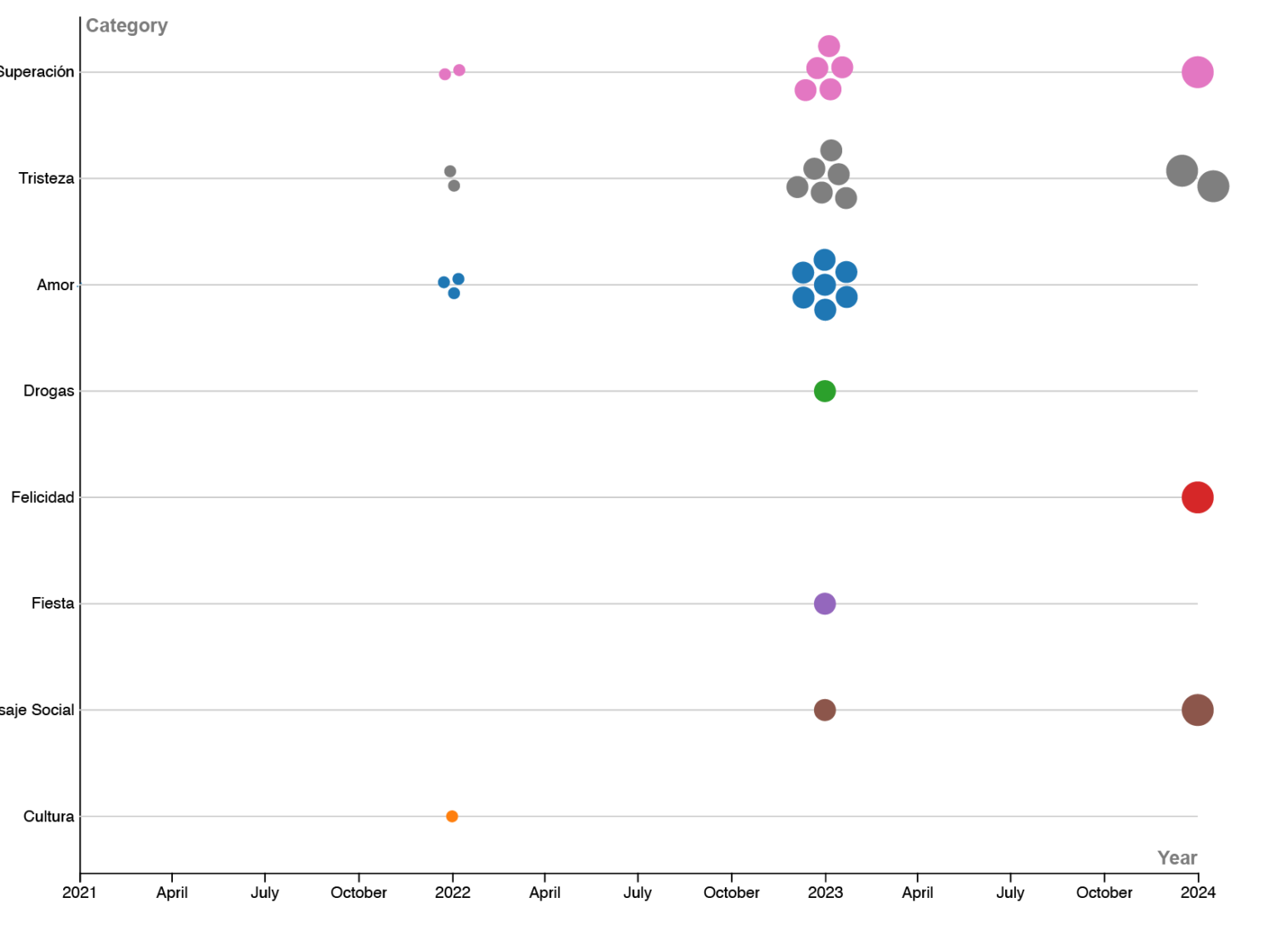
GRÁFICOS Y VISUALIZACIÓN DE DATOS
Desarrollo gráficos para visualizar hallazgos y tendencias.
Utilizamos RawGraphs para crear visualizaciones que nos permitan ver los hallazgos de manera clara y atractiva. RawGraphs es especialmente útil porque permite descargar los gráficos en formato SVG, facilitando su posterior edición y diseño.
{kind=link}
{kind=link}
{kind=link}
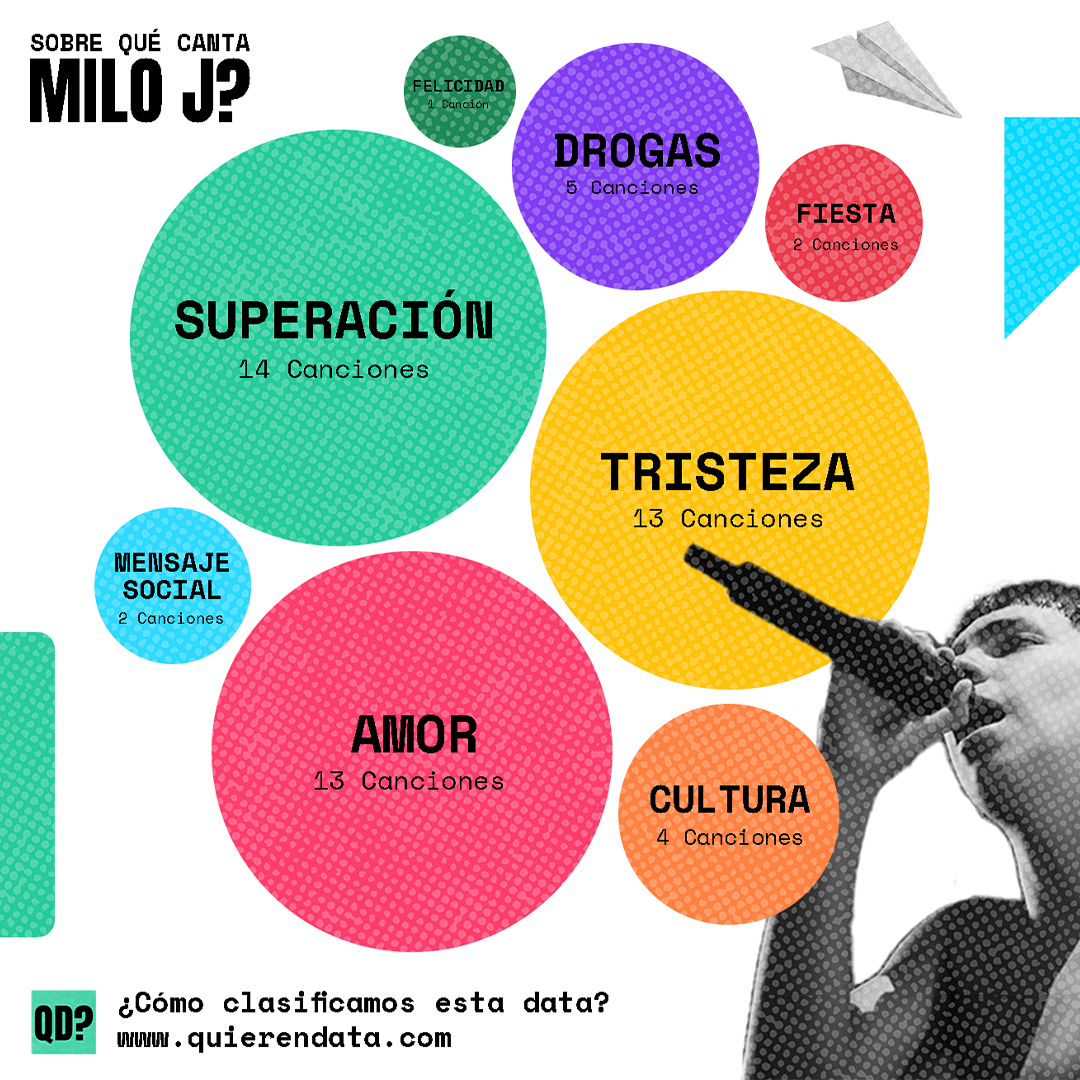
¿Cómo hacer esto más bonito? Usamos Illustrator y Photoshop como herramientas para diseñar, se realizan distintas piezas para los diversos canales como el Newsletter, Instagram, Imprimibles, Etc
{kind=link}
{kind=link}
{kind=link}